A partial, subjective opinion on Sentry
Last week I said on Twitter that I was not very impressed by Sentry and I'd like to explain it in more details.
@titanous @progrium do you have 2 or 3 advantages of Sentry over others? Considering switching off bc not impressed at all, maybe rollbar
— Jean-Baptiste Barth (@jbbarth) July 11, 2015First things first, this post is by no mean a way to denigrate Sentry developers hard work, and I hope they'll take it as a (hopefully) valuable feedback from some random user. And obviously, this article doesn't reflect the views of my current employer, where actually most people range Sentry from "good enough" to "freaking awesome I love it" (though I don't understand the latter ones...).
There are many reasons why a product might not fit your needs. I'm personally very sensitive to 2 of them:
- the right set of features : that's very subjective for sure, but I'd argue that in identified products like Sentry we can reach a consensus on some common use-cases ; also too many useless features is not a great sign (== lack of focus ; see OpenOffice^WLibreOffice for instance)
- the overall user experience : in other words, the execution of this very set of features. Especially are common things are hard to do, hard to find, unintuitive, or badly presented ?
Error reporting basics
Sentry is an error-reporting app. It aims at providing developers and operations teams some "insight into the errors that affect your customers". I identify roughly 3 major use-cases where you'd want to use something like this:
- case 1: you want to see the effects of an "event" (usually a freshly-finished deployment or an environmental outage) on your production errors ; which errors are the most frequent, how bad things are, etc.
- case 2: there's no external event but you managed to free up a few hours to tackle technical problems in your codebase, and Sentry can give you insight about the most frequent/problematic errors, or acknowledge that they are fixed
- case 3: you just hit a 500 error (or one of your customer contacting you) and want to identify what happened, which code raised the error, which server, is it a common problem, etc.
Error reporting tools can do much more, but those 3 cases are a good starting point:
- aggregated view of errors, with time constraint ("after the last deploy")
- aggregated view, without much time constraint ("all un-handled errors")
- non aggregated search + view
I think Sentry is OK for case 2, but case 1 has a terrible user-experience because it's hard to identify events or even select a time range, and 3 is basically KO because of search and aggregation as they are today.
Time selection problem
A minor but annoying one first. Sentry time-selector looks like this:
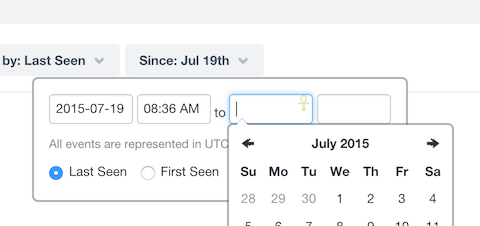
By default it starts back at 5 days ago. Meaning that if you want to identify what happened in the last few minutes/hours (case 1 and sometimes 3), you'll have to tweak start date and start hour. And it's no pleasant experience, since the hour doesn't have any kind of helper so you'll have to calculate the right hour in your head, and type it with your keyboard. Not hard, but when you do it 30 times a day, it quickly becomes a pain.
Most modern tools propose a simplified version of this by predefining common time ranges ("last 15 mins", "last hour", "last 4 hours", "last day", ...).
Search problem
I'm an infrastructure guy. When a customer experiences a 500 error, I don't care if it's a JS problem, a Django problem, or one of our backend systems that went wrong. But developers certainly do and they need to stay focused on the area where they have the most impact (in other words, backend developers don't have to be polluted by JS errors and vice-versa).
To achieve visibility and notifications separation, Sentry proposes the concept of "Teams", and inside teams, "Projects". That sounds OK at first, but from what I've seen it's not flexible at all, because there's no search option that is cross-team or even cross-project inside the same team.
People like me, my boss, our CTO, or our support team, absolutely need a transversal view so they can at least search things, identify efforts to be made depending on codebases, or simply identify which error a customer complaining on Twitter encountered (case 3).
The "Trends" and "New events" aggregations at team level are nice though, so I guess Sentry folks may be pushing in that direction some day.
Until then, the only reasonable options are: 1/ build your own dashboards (which might now be possible with the API announced 8 months ago), or 2/ stick everyone in the same team/project, but good luck for filtering things efficiently.
Aggregation problems
Sentry aggregates your errors so you can see exceptions from the same "kind" bundled with each other. That's cool!
Sometimes it aggregates things badly (in a way or another), but that's certainly not a trivial problem, and I don't have a magical solution for this. In a previous context I included in the app my own error reporting system and the only simple thing I could come up with was generating a hash from a clean version of the exception (without memory addresses or IDs) ; but that's way too basic for sure.
Anyway, my take on this is that if you cannot trust your aggregation system 100%, you should be able to disable it, at least selectively. Why? Because 1/ you don't want to miss important exceptions badly classified under non-important existing ones, and 2/ you don't want to lose data.
Lose data?!? Oh, sorry, forgot to talk about that. Sentry applies data sampling to incoming errors so you (or most likely it) doesn't get overwhelmed by a supposedly massive amount of incoming errors.
Come on! I'm a grown up, I can tweak my Postgres DB to store 30 or 40k records thanks. What I can barely afford though, is having a customer saying he encountered an error, and not finding it in my error reporting system (case "3" above).
So, I have 237 errors of one kind, you click on the report, you click on "Older event/sample" but at some point you understand that you're looping over the 3 same exceptions from yesterday, and you've basically lost the ability to retrieve finer grain informations.
Actually, I just clicked 5 times on "Older sample" on the SaaS version of Sentry, then 5 or 6 (?) times on "Newer sample" and provoked a 500 error. I think I'm ready to write a "this is normal" as Gary Bernhardt would.
To be fair there's one solution to this though: the raven client is pretty smart and it generates an "ID" that you can display on the error page to ease interaction with your customer. But customers don't always include all informations in error reports, and they even don't always contact support, so back to initial problem.
For now we identified errors that need actions and we're inserting the username inside the exception message so Sentry doesn't aggregate them. Yep, that's terrible. We hoped that the rules system would allow us to disable sampling for specific errors, but that was not the case (maybe an idea for later?).
An other option would be to not sample data and store everything, but fix thresholds (either TTL or quantity threshold) to define when data should be removed. Such a retention mechanism would be both more flexible and more reliable in my opinion.
And for errors we don't anticipate (most of them) ? Argh.
Maybe at least basic UI inside a given error could be improved, so the user can actually understand clearly which sample he's on, which one have been dropped, etc. Also there's nearly no information hierarchy on this page, so it's very hard to read (and I often miss informations like comments from my colleagues), but that shouldn't be too hard to improve I guess.
A conclusion
To be honest, there are many other things that Sentry might get right. One being that it integrates with many languages and that the protocol seems to be hackable enough to add more integrations. There are also a lot of advanced features that I don't care much of, given that the basics are not OK for me, but still, notifications, acknowledgements, rate limiting, origin security are nice things to have.
Anyway that's not by congratulating about how some sides of a project are good that software improves. I sincerely hope Sentry will improve in the next few months/years, but for now I'm ready to try alternatives or even build my own raven-compliant error reporting tool.
NB: there's no comment on this blog, but if some Sentry hackers find those criticisms valuable, don't hesitate to ping me back so I can follow the discussion elsewhere, being a GH issue, HN, Reddit, or anywhere... Again, happy to help if I can!