Riak CS: store your files on top of Riak
Last month Basho Tecnologies, the company behind Riak, open-sourced Riak CS, the storage software they built on top of Riak. Riak is already known for being a distributed, reliable, fault-tolerant database. I already explored a bit Riak back in 2011 here and here.
Riak CS has an Amazon S3 compatible API. It's nice because there are already many tools available which support S3 API, so there's already a bunch of client code and libraries compatible with Riak CS as a file storage system. Note that this is not unique: that's also the case of OpenStack's Swift, EMC's Atmos, Eucalyptus or Nimbus.io, though I don't have experience with any of them. Basho provides some comparison points in their docs if you're interested.
Installing Riak CS
Installing Riak CS for test and development purposes is easy with The Riak CS Fast Track,
especially Building a Virtual Testing Environment.
No need to repeat Basho docs here, just follow the steps they suggest. Note that sometimes Vagrant fails
just after the box download, you might want to retry the vagrant up command then.
Just a quick note here: I first tried to follow the process 2 days after Basho open-sourced Riak CS. It was a bit rough around the edges back then but the Basho team has been incredibly responsive and helpful to get things running properly. I rarely saw such a level of care before, it's really awesome and it just makes me want to work more with Riak/Riak CS in the future. The whole process has been made as smooth as possible since then, but if you have a problem, I encourage you to ping them on IRC or on the mailing list.
After the Vagrant box has been installed and provisionned successfully, you should have a running Riak CS node (under Ubuntu 12.04) and your admin credentials in hand. Time to play!
Basic bucket/file usage
You can follow the Testing the Riak CS Installation
page. I recommend installing a recent version of s3cmd through the tarball if you're under MacOSX.
I'll skip the -c ~/.s3cfgfasttrack parameter below and assume you had left the config file in
its default place like me.
You should now be able to create a new bucket:
s3cmd mb s3://test-bucket
List buckets through ls:
s3cmd ls
Put a file in the newly created bucket:
s3cmd put /etc/hosts s3://test-bucket
See the file is here in the bucket:
s3cmd ls s3://test-bucket
Get the file, optionnally providing a destination path:
s3cmd get s3://test-bucket/hosts /tmp/hosts
And finally remove it from the bucket if you want:
s3cmd del s3://test-bucket/hosts
Pretty standard features for a file storage service or even any "filesystem". There are plenty
of other standard features (sync a subtree, move, copy, rename, symlink, etc.). There are also
advanced features such as ACLs depending on the user, you may run s3cmd --help and try to
play with them yourself if you want.
Managing users
The Fast Track install we followed before comes with a handy tool to manage your Riak CS users, "Riak CS Control". It's a simple Ember.js app that allows you to issue basic CRUD operations on your users and change/revoke their secret key if needed.
It should be started by default on port 8000, so just point your browser to http://localhost:8000 and see what can be done by yourself!
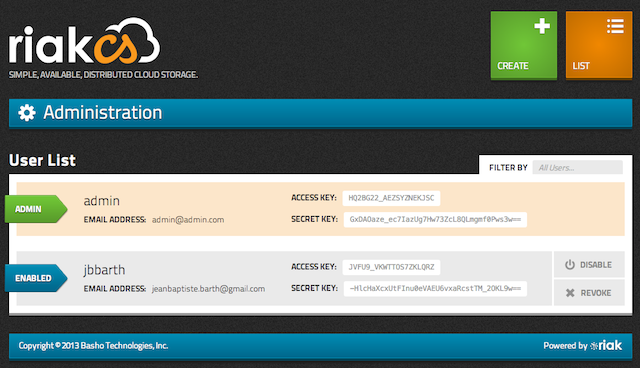
If you need more maybe you should have a look at Riak Control (which manages Riak, not Riak CS, and is a successor to Rekon if I'm not mistaken).
Monitoring
If you want to dig into what your Riak CS cluster is doing under the hood, you might want to retrieve global metrics. Those metrics are exposed through the HTTP interface but they require authentication.
I don't have much experience with that, Authentication doesn't seem easy to achieve in a web browser or with curl directly. More explanations here.
The s3curl tool will help you sign your requests automatically
depending on your secret key. You can download it and move the perl script to /usr/local/bin/s3curl
so that it will be easy to use. You'll also have to configure ~/.s3curl, in my case:
%awsSecretAccessKeys = (
personal => {
id => 'HQ2BG22_AEZSYZNEKJSC',
key => 'GxDAOaze_ec7IazUg7Hw73ZcL8QLmgmf0Pws3w==',
},
);
Just to test it works, you can upload a file with s3cmd and then test you retrieve it with s3curl:
s3cmd put /etc/hosts s3://test-bucket
Then:
http_proxy=localhost:8080 s3curl --id personal -- http://s3.amazonaws.com/test-bucket/hosts
#=> should display your /etc/hosts file
If that doesn't work, the --debugflag can be useful to see the request/response cycle and understand
what happens.
Now that you've a working s3curl config, you can retrieve some statistics:
http_proxy=localhost:8080 s3curl --id personal -- -s http://s3.amazonaws.com/riak-cs/stats | python -mjson.tool
I used the -s option to remove curl progress informations, and the | python -mjson.tool to pretty-print
the result. You'll see you access various global statistics about your Riak CS cluster, great isn't it ? If
you need more "real-time" debugging Riak CS has some dtrace probes but I didn't try it myself. The full doc
is available here.
There's also a magic usage bucket which exposes usage statistics for each user, docs
here and in the following sections.
A conclusion
I think that's enough as a first overview of Riak CS. Here are a few points I leave here as a conclusion:
1/ Riak CS leaves on top of Riak. So you can expect it to be reliable, easy to scale, and easy to operate. And it has some monitoring goodies so day-to-day monitoring shouldn't be a problem.
2/ Riak CS is run by Basho. From my 2 short experiences in Basho's world, you can expect a truly amazing support. Of course commercial support is recommended if you want extra features or some guarantees, but that's not my case for now.
3/ The ecosystem is already here. For instance there's already a redmine_s3 plugin that just lacks proxy support to work with Riak CS. I bet I'll work on that in the next few weeks so that I'll be able to store big files in my Redmine instance for free.
To sum it up, I can't wait to have the opportunity to dig into Riak CS a bit more! Stay tuned ;-)